Image segmentation
![]()
4 min read (801 words)
Table of contents
What is image segmentation? Fully Convolutional Network U-Net LinkNet Pyramid Scene Parsing Network - PSPNet Feature Pyramid Network - FPN How to cite References
What is image segmentation?
Image segmentation is another essential and traditional computer vision problem. It involves semantic segmentation, where each pixel of the target is labeled with a specific class and instance segmentation, which incorporates the separation of objects on top [1]. These two tasks have been suggested to be merged into a novel panoptic segmentation [2]. We will further refer to semantic segmentation since it captures the primary idea its concept can be transferred to the other types. There were several computational techniques popular back in the early days of digital image science. These include, segmentation using morphological operations, Markov random fields [3], active contours [4, 5] and levels sets [6]. However, the research has undergone a tremendous shift after the proposition of convolutional neural networks and deep learning in general. The named techniques are not widely used nowadays after being overshadowed by the success of highly accurate deep neural networks. Although many preceded there are various traditional methods, this writing will touch on approaches from a deep learning perspective.
In more simple terms, the image segmentation task is the identification of pixel groups that are together. From the perspective of machine learning, it is a subset of clustering problems. In its simplest form of a fully convolutional network model [7].
\[y_{i j}=f_{k s}\left(\left\{x_{s i+\delta i, s j+\delta j}\right\}_{0 \leq \delta i, \delta j \leq k}\right)\]Given \(k\) size of kernel, \(s\) stride, \(f_{ks}\) layer type (pooling, activation, etc.) for location \((i,j)\). One of the prevalent cost functions for optimization of deep neural networks in semantic segmentation has been binary cross-entropy:
\[L_{B C E}(y, \hat{y})=-(y \log (\hat{y})+(1-y) \log (1-\hat{y}))\]where \(\hat{y}\) defines the predicted value by the prediction model for the target \(y\).
Another common function, Dice loss, is particularly applicable in biomedical applications. It evaluates segmentation via calculating the overlap areas between the predicted map and ground truth images:
There are still active efforts to research loss functions in deep learning segmentation. Despite their numbers, loss functions can be grouped into different categories, either rewarding or penalizing particular attributes (data of distribution, region, boundary, or compound) [8]. This is illustrated schematically in figure below. The recipe to prefer the utilization of one over the other is rather empirical. Therefore, understanding the nature of data and plentiful experimentations is a rule of thumb for biomedical research.
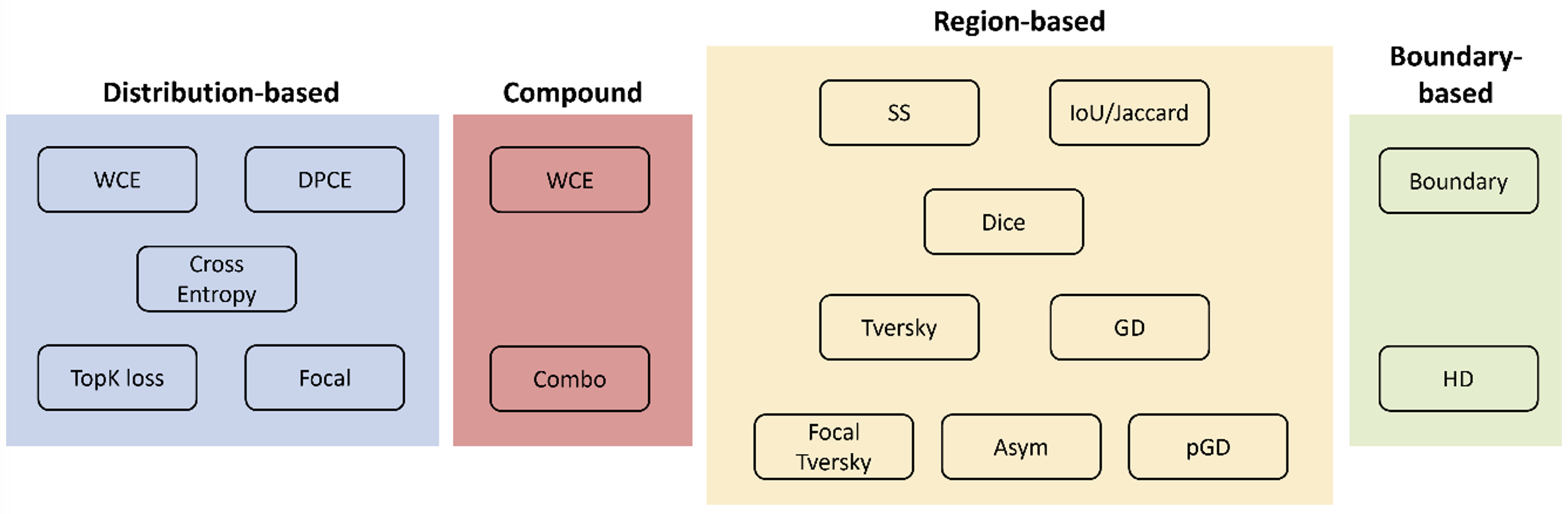
- Fig. 1. Taxonomy of loss functions
Taxonomy of losses into different groups:
- distribution-based (data of distribution)
- region-based loss (rewarding or penalizing region)
- boundary-based loss (rewarding or penalizing boundary)
- compound loss (combines several)
Fully Convolutional Network
First end-to-end, pixels-to-pixels trained network, extension from traditional convolutional neural network (AlexNet, VGG and GoogLeNet) to address semantic segmentation task [9]. In this setup, features from deep, coarse layer of convolutional network are extracted from fine-tuning. Additional shallow layer was included to prodice detailed segmentations. The reported network exceeded 20% of mean IoU compared to previously state-of-the-art NYUDv2 and SIFT FLow, and resulting in a quicker inference as well.
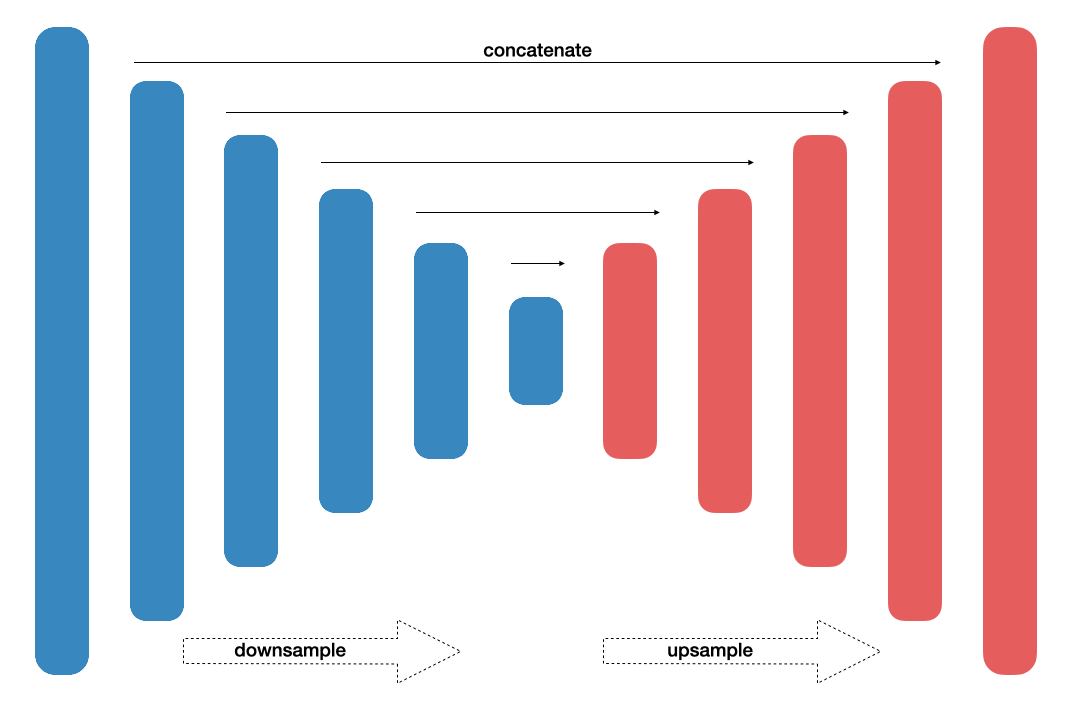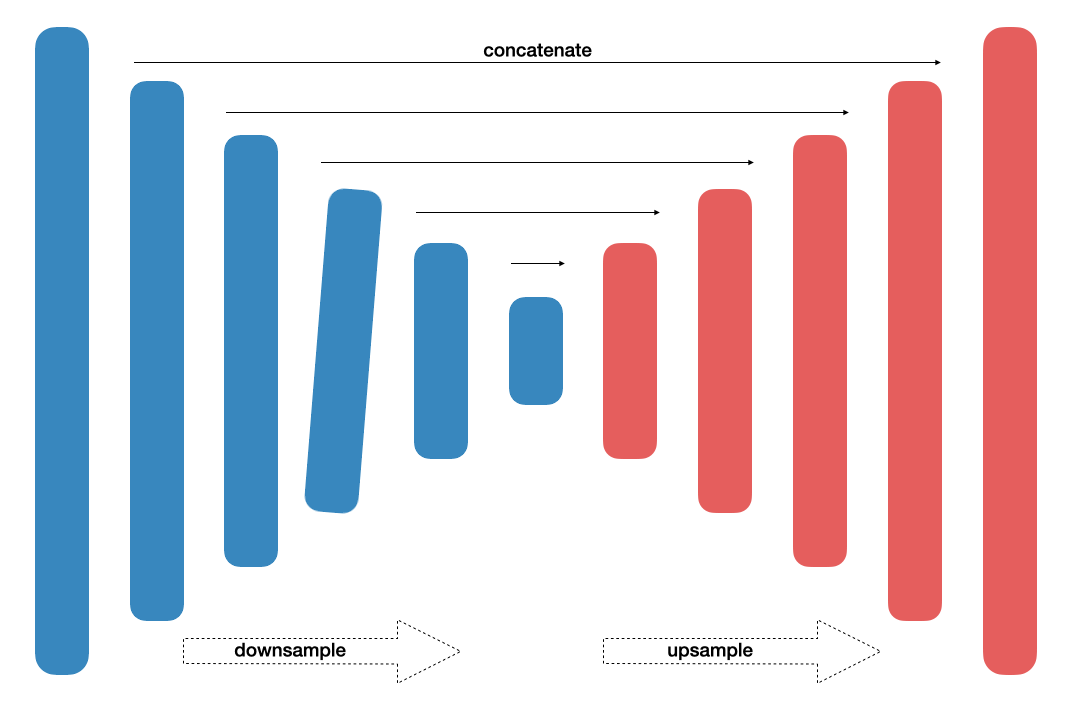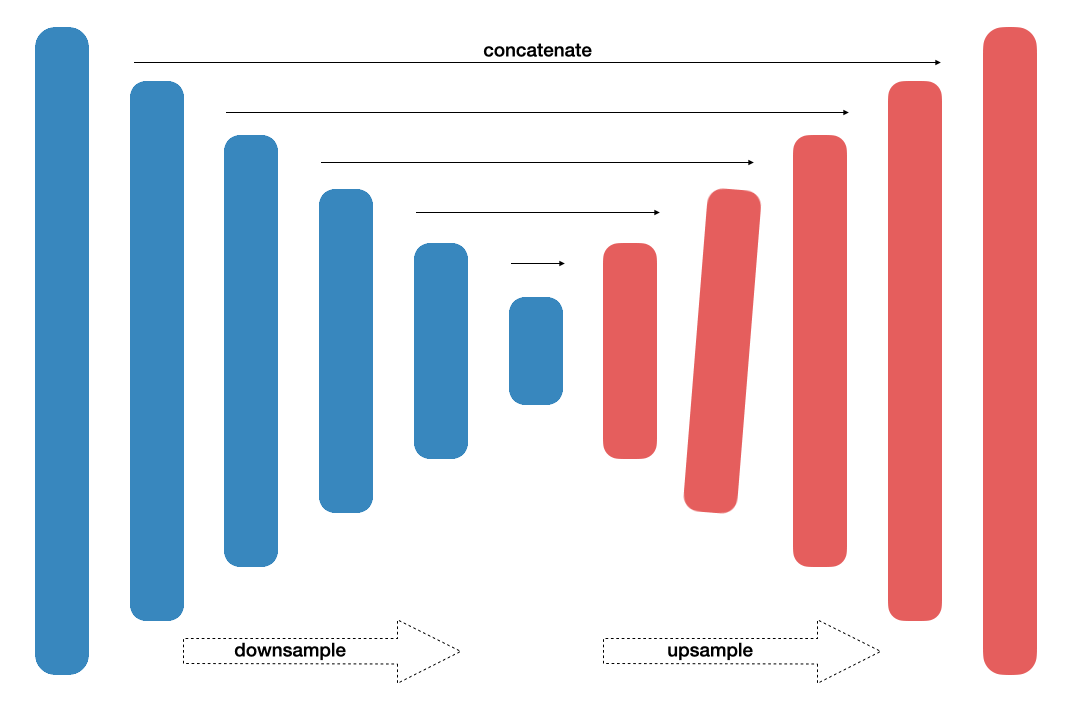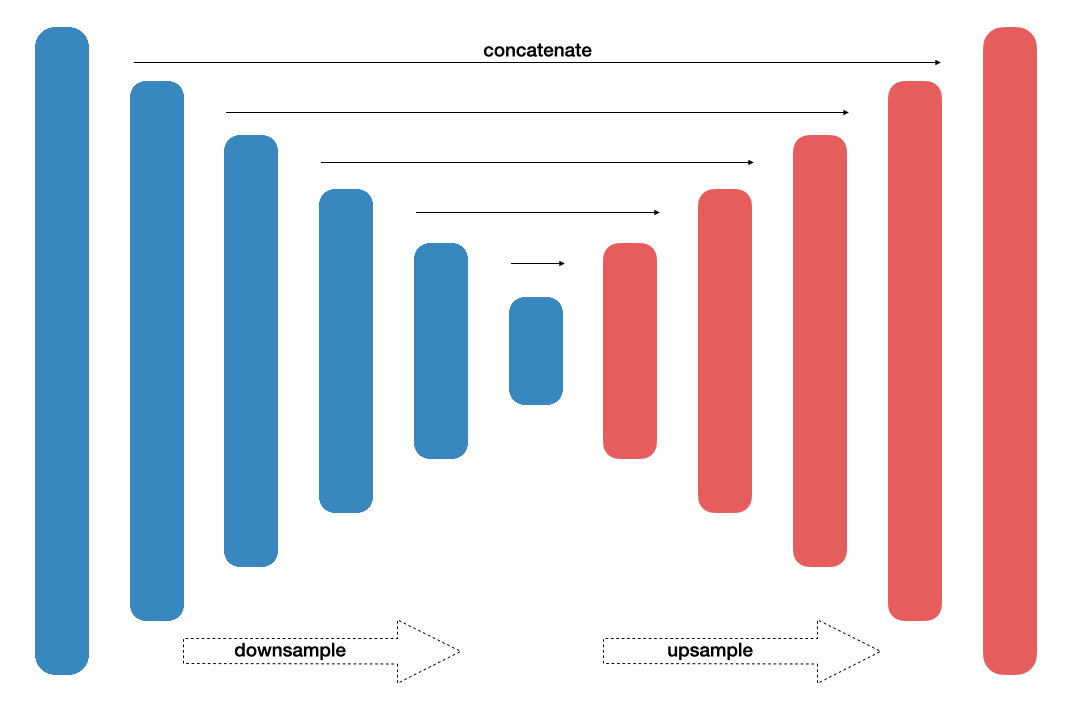
U-Net
Originally proposed as a solution for biomedical ISBI Cell tracking challenge, this network [10] has been named for its similarity with U-shape. The architecture contains contracting path and expanding path. In the contracting path, context information is captured, whilst in a symmetric expanding path, precise localization is enabled. Previous to this work, the best method relied on sliding-window convolutional network. Training trategy utilizing augmentation has been reported to give efficient results. These include: shift, rotation invariance as well as various deformations and gray value variations. With this setup only a few training samples were enough to achieve high accuracy results. Weighted loss is suggested to address the border separation between foreground and background pixels.
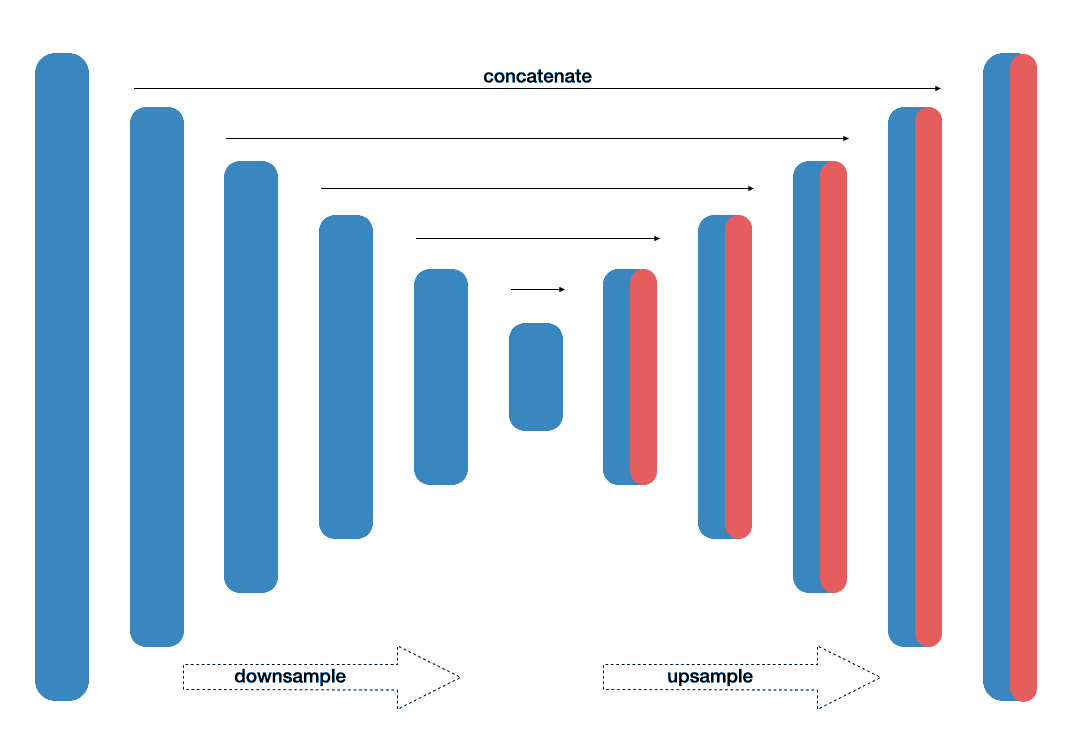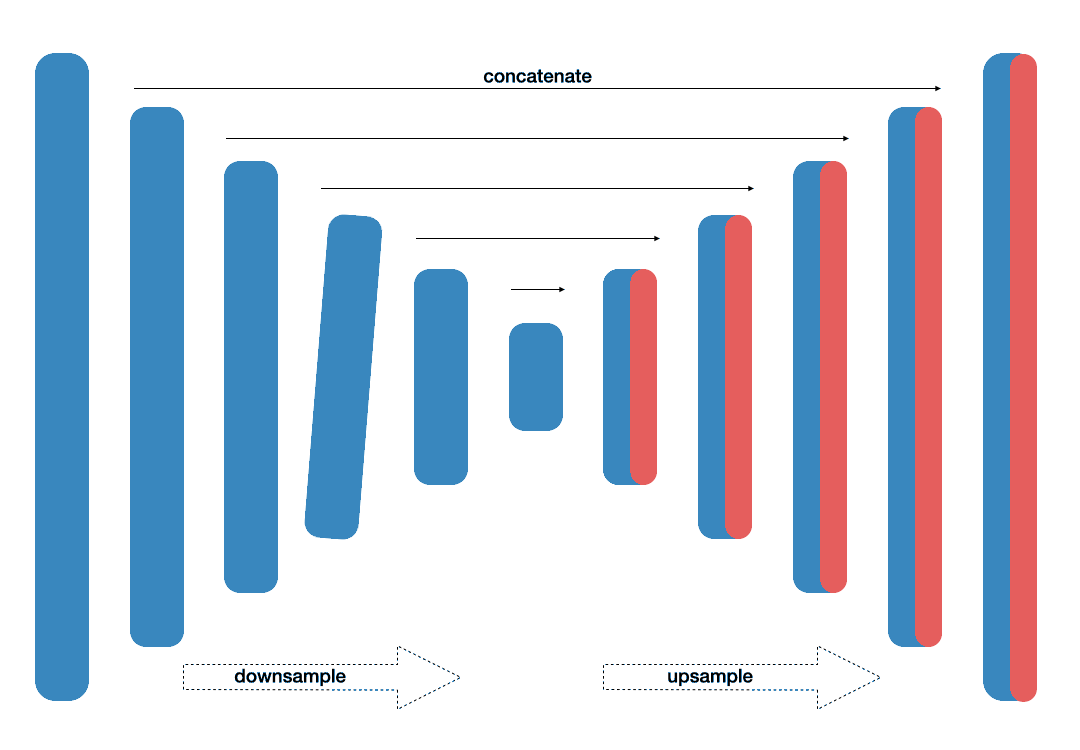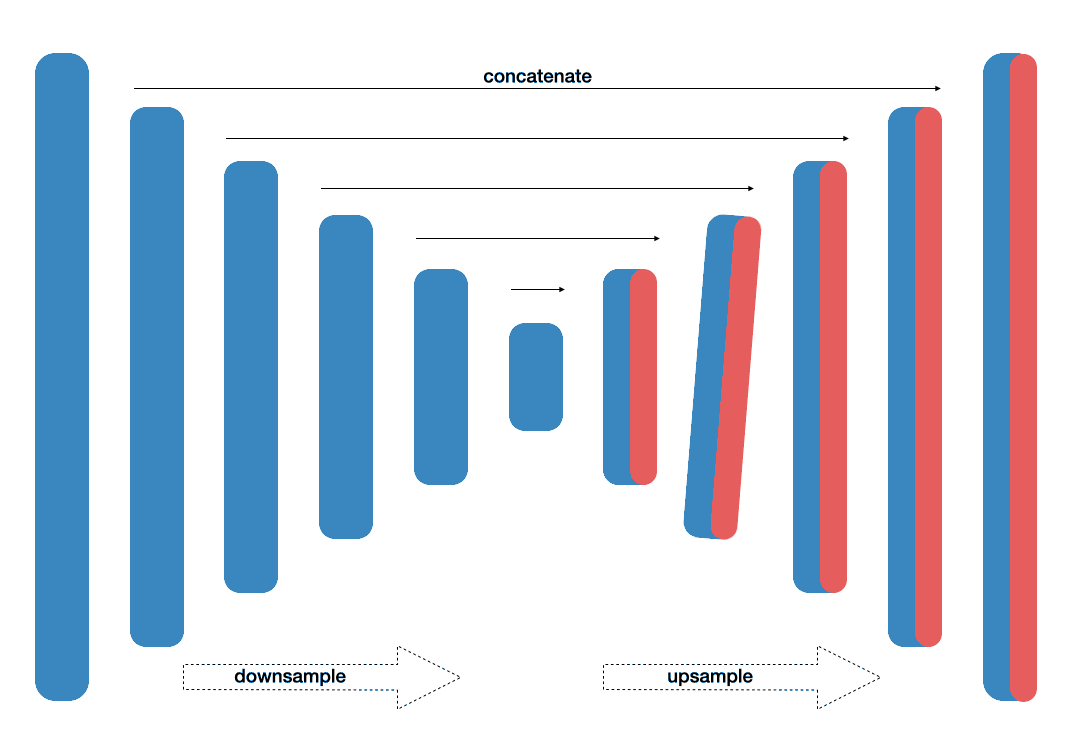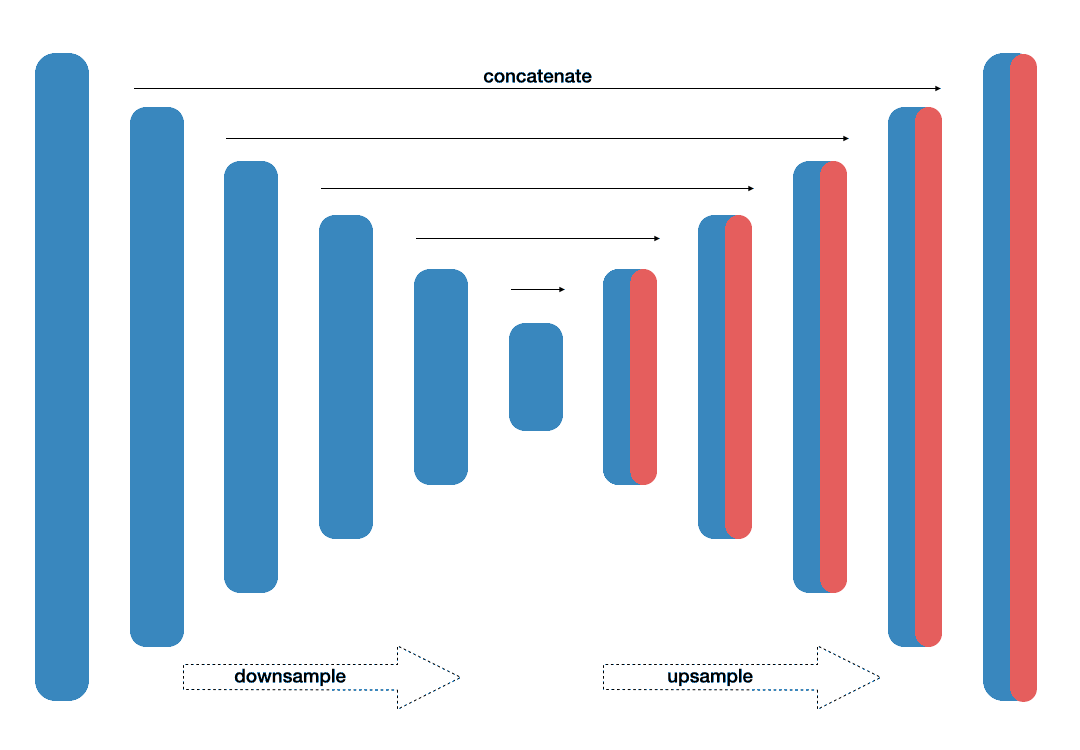
- Fig. 2. U-Net
LinkNet
Focusing on efficiency, this architecture [11] produces equally accurte results. With 11.5 million parameters and 21.1 GFLOPs, this neural network targeted real-time applications. Traditional convolutional module was replaced with residual encode-block. Efficiency of the network also resulted from operation of adding, rather than stacking.
- Fig. 3. LinkNet
Pyramid Scene Parsing Network - PSPNet
Scene parsing, very close to semantic segmentation in nature (i.e. dividing image into segmentes) has been challenging due to various reasons. These include mismatched relationship (producing car inside water), confusion of similar categories (i.e. building with tower), inconspicuous classes (pillow overshadowed with bed). Therefore, understanding global contextual inforamtion is necessary for network to solve this issue. In the proposed PSPNet network [12], the mechanism to address is pyramid pooling module combined have produced state-of-the-art performance on PASVAL VOC benchmark (85.4%s). This is due to the architecture, which is able to harvest different sub-region representations.
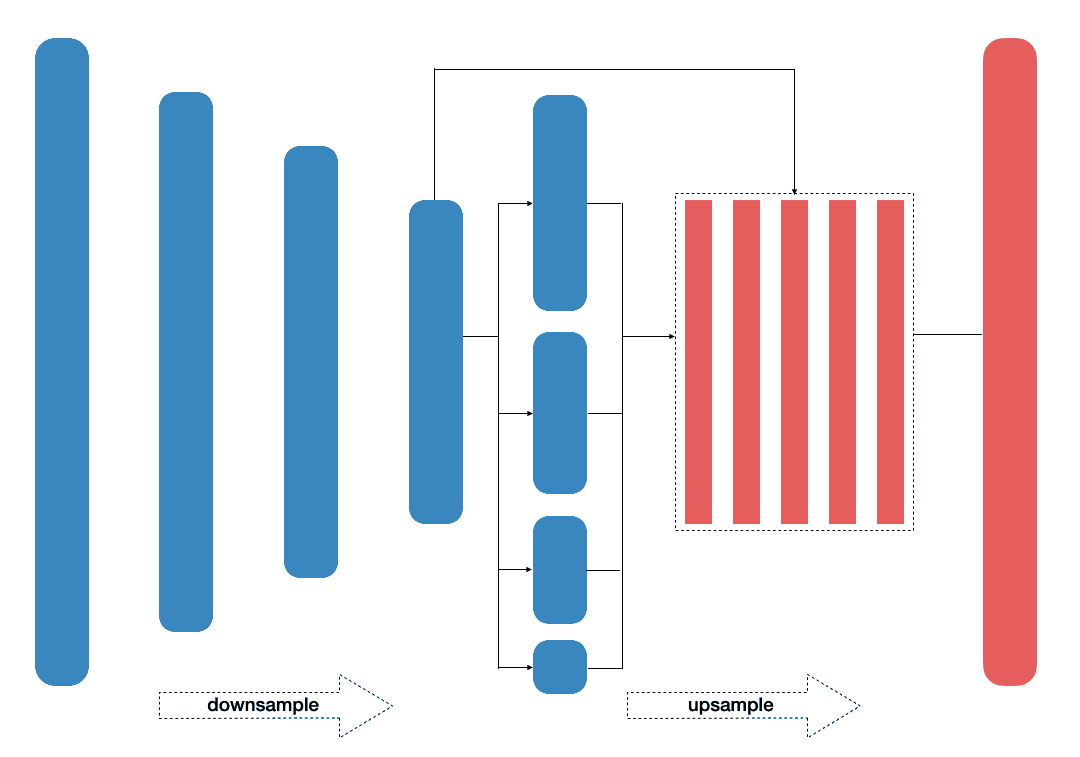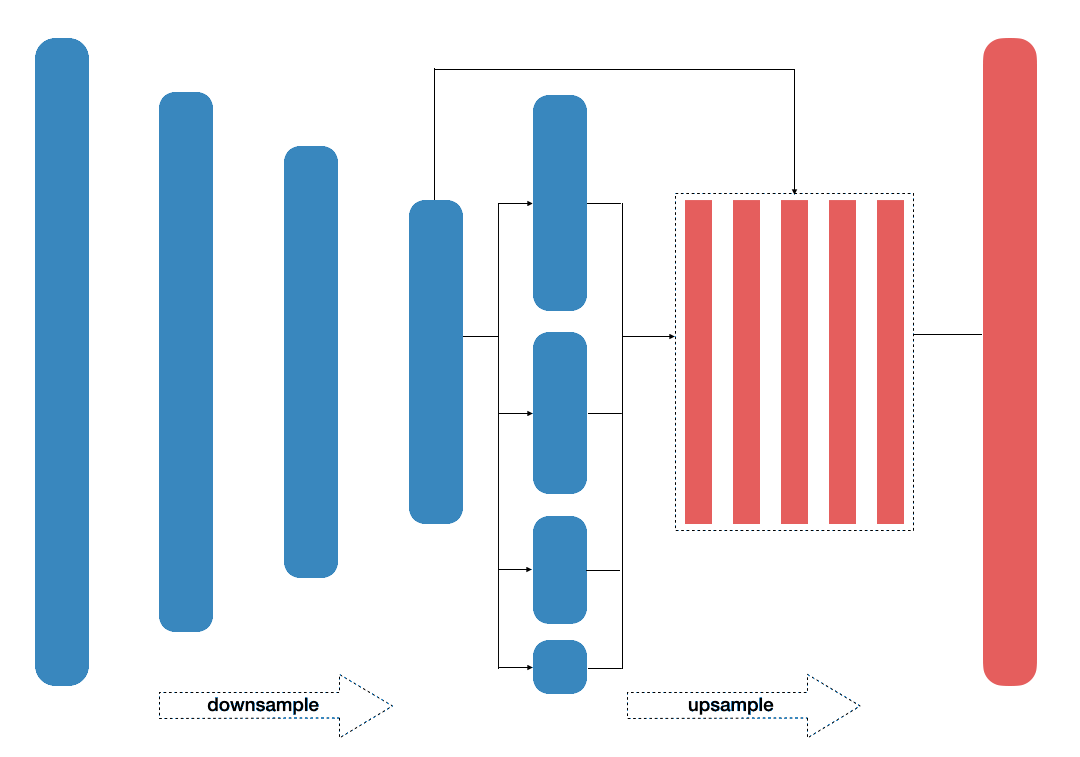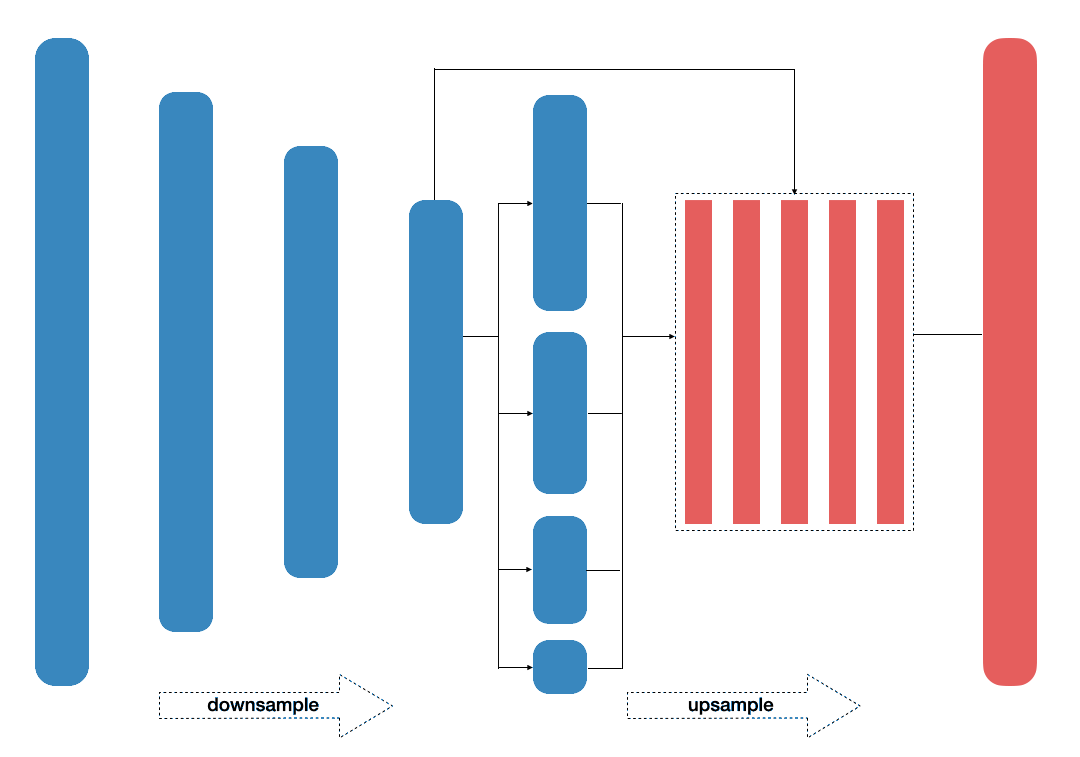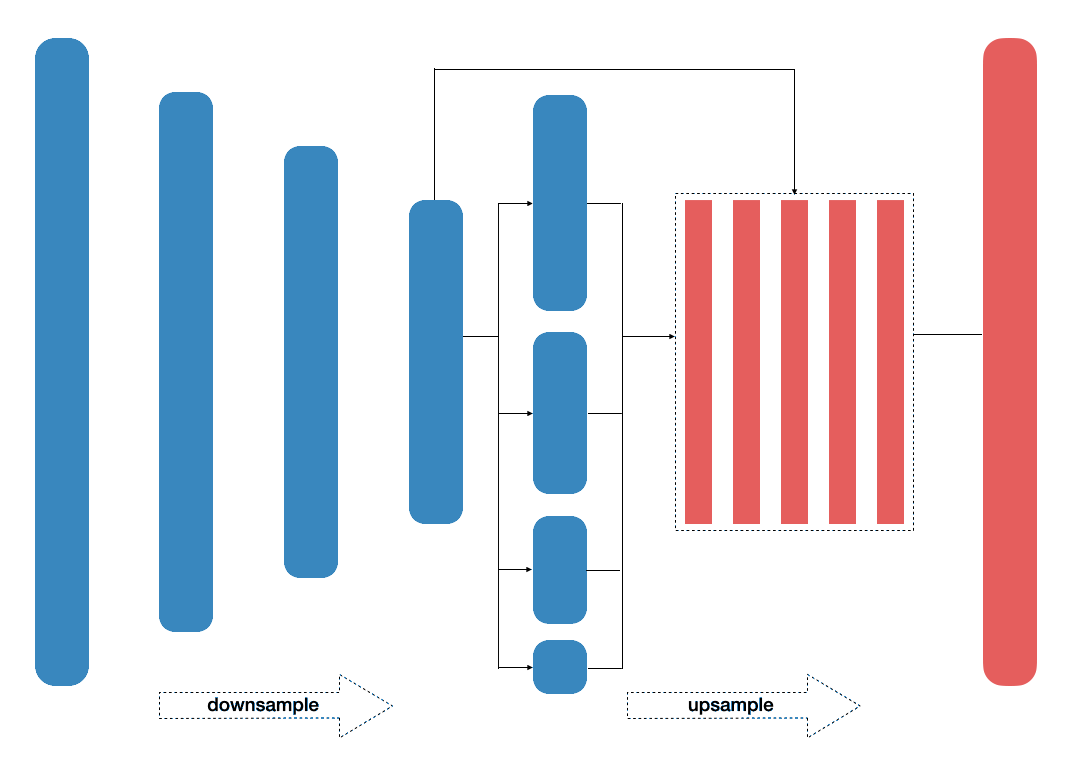
- Fig. 4. PSPNet
Feature Pyramid Network - FPN
Feature pyramid [13], the building block of vision recognition tasks, has implications to segmentation task. It was originally proposed in Faster R-CNN paper used for object detection. Despite its marginal extra cost, pyramidal hierarchy of deep convolutional networks allow inhearitance of multi-scale, high-level feature maps. It serves as backbone and generic feature extractor model to extend accurate models upon. In object detection, it achieved highest score in COCO 2016 task with 6 FPS inference.
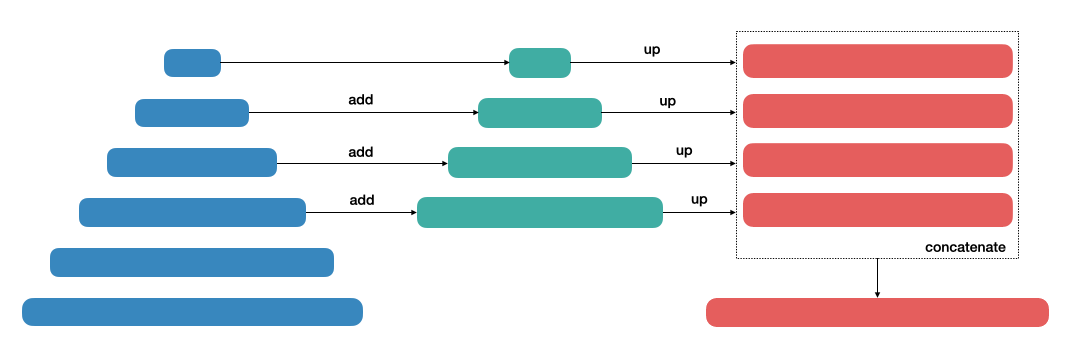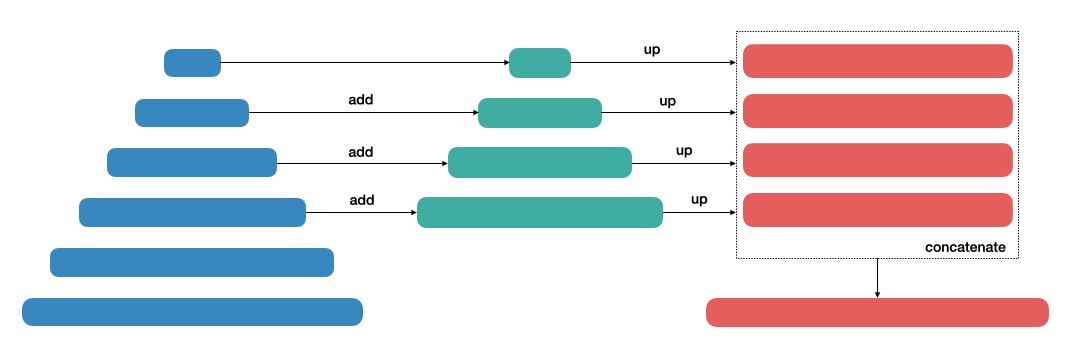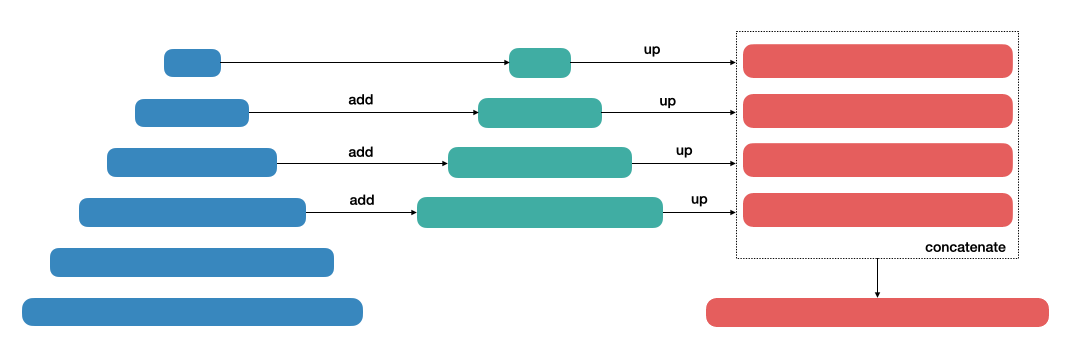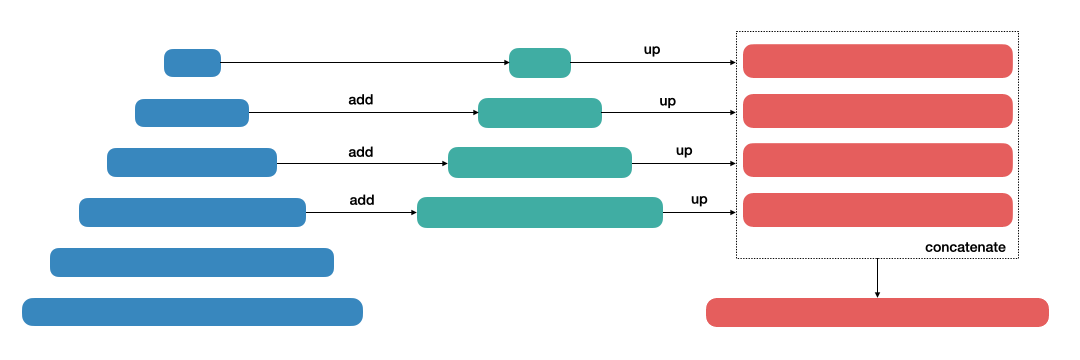
- Fig. 5. FPN
How to cite
Askaruly, S. (2021). Image segmentation. Tuttelikz blog: tuttelikz.github.io/blog/2021/11/segmentation
References
[1] Szeliski, R., 2010. Computer vision: algorithms and applications Springer Science & Business Media.
[2] Kirillov, A., He, K., Girshick, R., Rother, C. and Dollár, P., 2019. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9404-9413).
[3] Greig, D.M., Porteous, B.T. and Seheult, A.H., 1989. Exact maximum a posteriori estimation for binary images. Journal of the Royal Statistical Society: Series B (Methodological), 51(2), pp.271-279.
[4] Mortensen, E.N., 1999. Vision-assisted image editing. ACM SIGGRAPH Computer Graphics, 33(4), pp.55-57.
[5] Blake, A. and Isard, M., 2012. Active contours: the application of techniques from graphics, vision, control theory and statistics to visual tracking of shapes in motion. Springer Science & Business Media.
[6] Sethian, J.A., 1999. Level set methods and fast marching methods: evolving interfaces in computational geometry, fluid mechanics, computer vision, and materials science (Vol. 3). Cambridge university press.
[7] Long, J., Shelhamer, E. and Darrell, T., 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3431-3440).
[8] Ma, J., Chen, J., Ng, M., Huang, R., Li, Y., Li, C., Yang, X. and Martel, A.L., 2021. Loss odyssey in medical image segmentation. Medical Image Analysis, 71, p.102035.
[9] Long, J., Shelhamer, E. and Darrell, T., 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3431-3440).
[10] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation In: Navab N, Hornegger J, Wells W, Frangi A, editors. Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015). Lecture Notes in Computer Science, vol. 9351. Springer: 2015. p. 234–41
[11] Chaurasia, A. and Culurciello, E., 2017, December. Linknet: Exploiting encoder representations for efficient semantic segmentation. In 2017 IEEE Visual Communications and Image Processing (VCIP) (pp. 1-4). IEEE.
[12] Zhao, H., Shi, J., Qi, X., Wang, X. and Jia, J., 2017. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2881-2890).
[13] Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B. and Belongie, S., 2017. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2117-2125).