Basic parallelism in Python
![]()
5 min read (848 words)
Table of contents
Introduction
Imagine unlocking the potential of your devices: your smartphone seamlessly executing a handful of functions without freezing, and your PC delivering stunning graphical animations and gaming experiences by solving multitudes of complex computations. What’s the magic of such modern software technology? We must acknowledge parallel processing – a radical approach to empower gadgets to simultaneously execute numerous processes, thereby significantly increasing efficiency. If you are already intrigued, I’d like to invite you to dive deeper into the world of parallel processing and explore its technical side at an introductory level.
Let me begin by addressing the question: What is parallel processing? Put simply, it is a computational paradigm that enables the execution of multiple tasks simultaneously. Unlike sequential execution, parallel processing leverages the computational capacity of multiple cores, processors, or nodes, distributing tasks across hardware for increased efficiency. As for why it can be useful, there are several strong reasons:
- Increased performance: Parallelization accelerates task execution by leveraging multiple processors or cores simultaneously, resulting in improved overall system performance.
- Efficient resource utilization: Parallel computing optimizes resource usage by distributing workloads across multiple processing units, maximizing the utilization of available hardware resources.
- Scalability: Parallelization enables applications to scale effectively, accommodating larger datasets and more complex computations, particularly in the context of multicore processors.
- Accelerated problem-solving: Parallel processing enhances problem-solving capabilities by breaking down complex tasks into smaller, independent subproblems that can be solved concurrently, thereby reducing time-to-solution.
Background
Now that we’ve explored the benefits of parallel processing, let’s delve into its fundamental elements. By understanding these basics, you’ll be better equipped to recognize key differences between related concepts and grasp the power of parallel computing.
Concurrency vs parallelism
In concurrency, computational tasks operate independently but not necessarily simultaneously. The switching between tasks might occur so rapidly that it might appear as though they are progressing at the same time. On the other hand, in the case of computational tasks during parallelism, which are hosted on multiple processors or cores, they are executed perfectly simultaneously. The image below provides a brief visual representation of this concept.
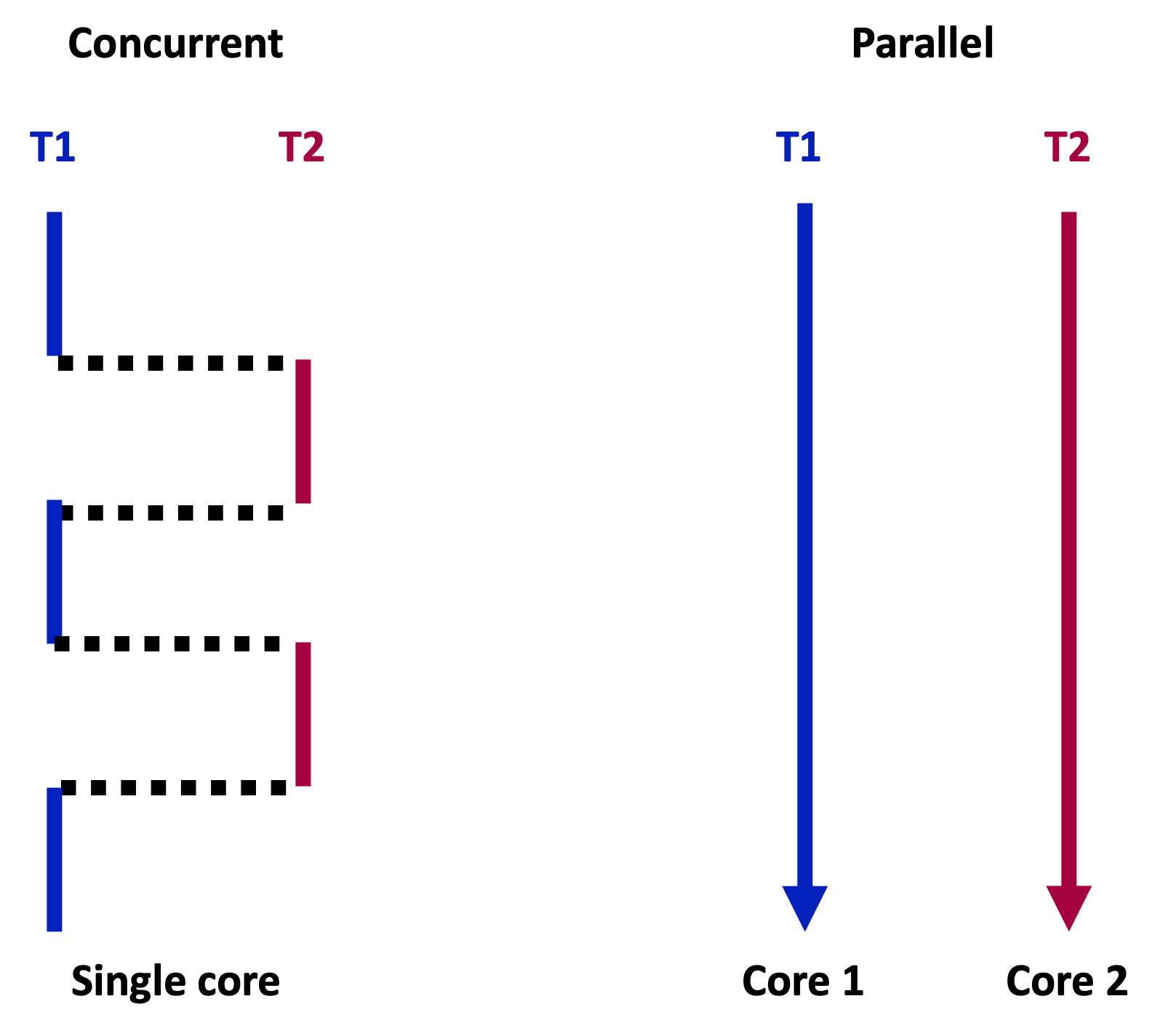
- Fig. 1. Simplified illustration of two tasks executed under concurrency and parallelism
Thread vs process
Computational multitasking is accomplished with the help of the smallest units of execution, either using threads or processes. A thread is a lightweight, independent, shared memory space component running within the program’s process. On the other hand, a process is heavier, having its own memory space instance of a computer program. It self-contains resources for execution and maintains a higher degree of isolation. Thus, specialized communication mechanisms (IPC) are usually required for inter-process communication. Their main distinctions are summarized in Table 1 and Figure 2 below.

- Table 1. Principal differences of thread and process
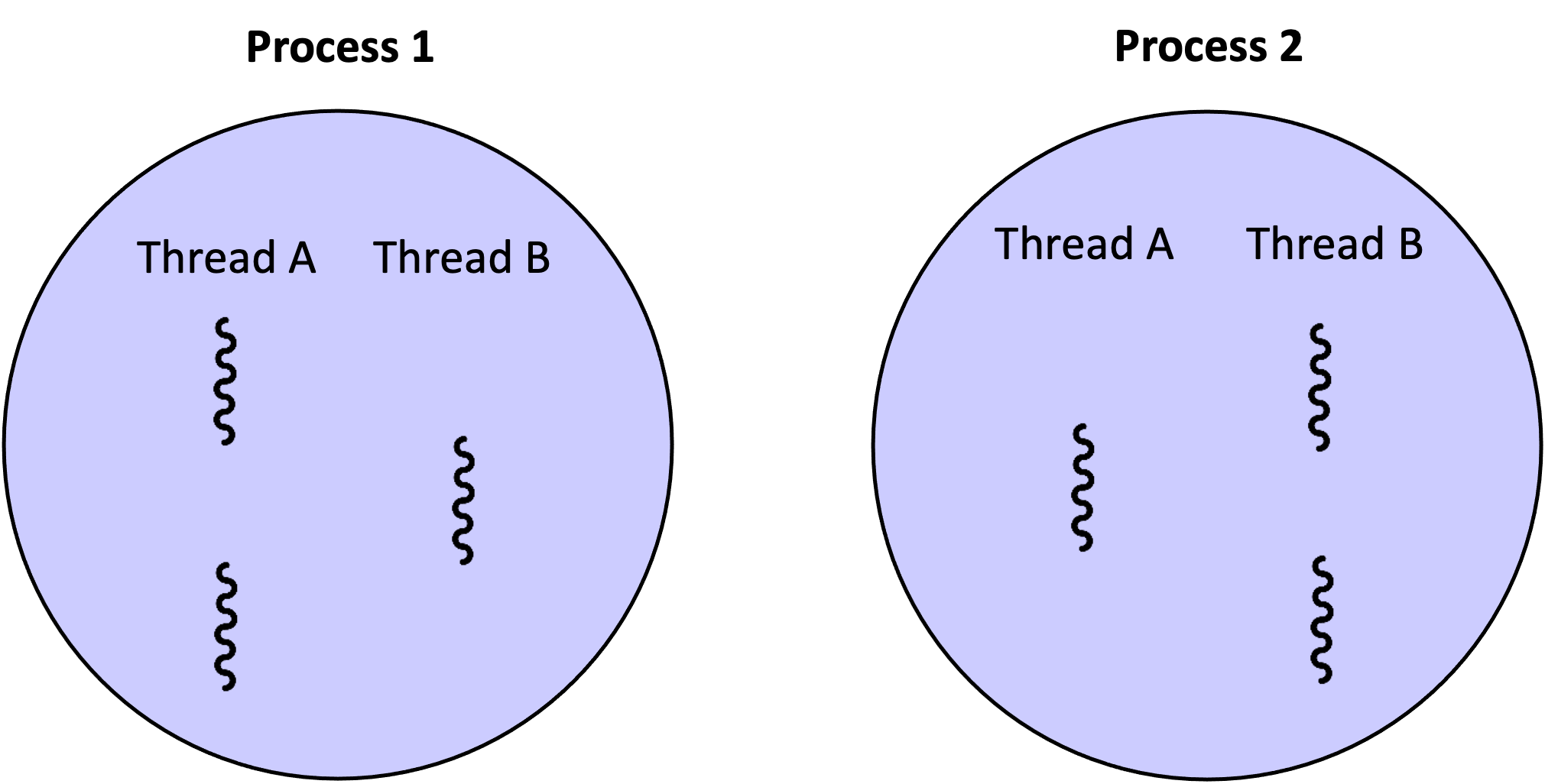
- Fig. 2. Two processes executing multiple concurrent threads
Starting a thread or process in Python using the standard threading and multiprocessing module is straightforward:
| A. Starting a thread | B. Starting a process | |
|---|---|---|
import threadingthreading.Thread(target=func, args=(args,)).start() |
import multiprocessingmultiprocessing.Process(target=func, args=(args,)).start() |
Let’s conduct a small experiment on an embarrassingly parallel task. Our objective is to calculate the square for each element from 1 to 100,000. We’ll implement this task using both previously introduced paradigms—threads and processes—in Python. Furthermore, we’ll vary the number of threads/processes to observe their respective effects and compare their performance. To facilitate your understanding, I’ll provide the results based on my setup.
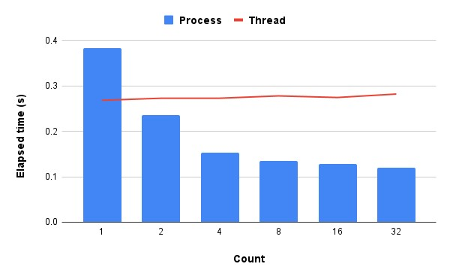
- Fig. 3. The effect of increasing the number of processes/threads in Python for the embarrassingly parallel task
The values of the elapsed time may vary on your machine compared to what is presented here; however, the trend should remain consistent. Increasing the number of processes typically results in faster computation, whereas increasing the number of threads may not yield similar benefits. This discrepancy occurs due to the Global Interpreter Lock (GIL).

GIL
Global Interpreter Lock (GIL) in Python acts as a guard, preventing simultaneous access to Python objects. It ensures that only a single thread can execute within the interpreter at any given moment, even in a multi-threaded environment. Due to this limitation imposed by the GIL, there might be no improvement with threading compared to using processes. For an in-depth look at threads and the GIL, I recommend this talk [1], which covers the nitty-gritty details.
On the other hand, when starting a process in Python, its own interpreter is created along with a separate memory space, allowing for true parallelism. Several processes created within Python can be distributed across multiple cores, potentially leading to better performance.
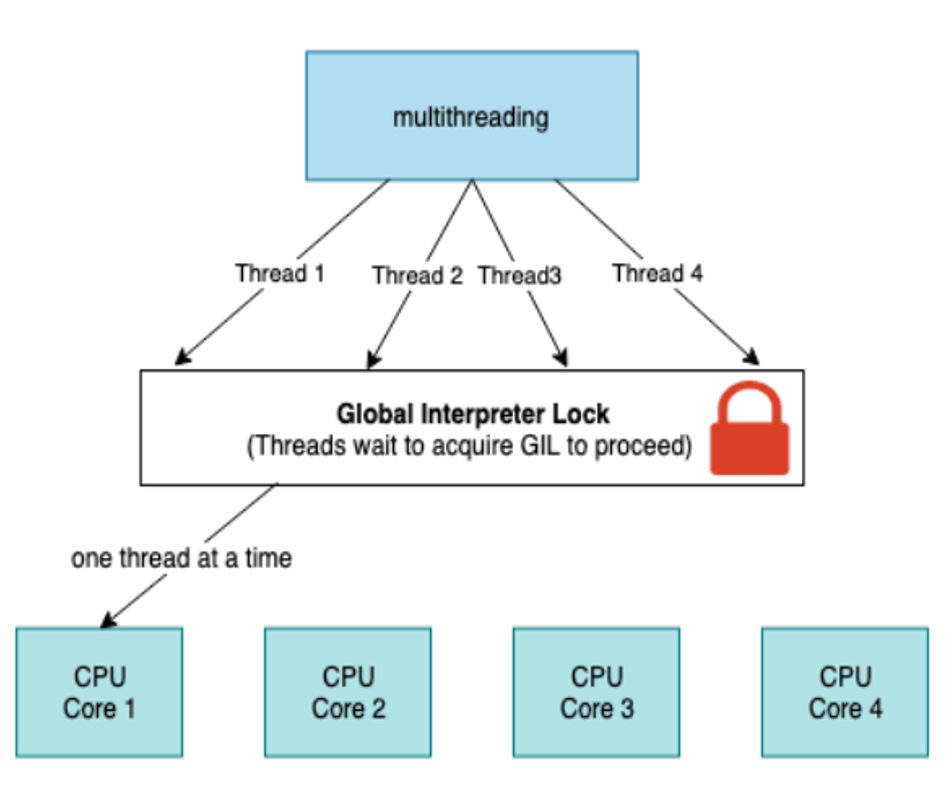
- Fig. 5. Global Interpreter Lock (GIL). The interpreter permits the execution of only one thread at any given moment.
When deciding whether to use threads or processes, it’s beneficial to consider the nature of the task at hand. Processes are typically preferred for CPU-bound tasks, which involve CPU-intensive operations or tasks that spend most of their time performing computations. For example, calculating prime numbers, as shown in Appendix A1, is representative of this category.
On the other hand, threading is more suitable for I/O-bound tasks, which spend the majority of their time waiting for input/output operations to complete. Examples of I/O-bound tasks include reading or writing into files, network communication, and interacting with a database, as illustrated in Appendix A2.
Amdahl’s law
Once we recognize that parallelization can bring potential efficiency benefits, it’s prudent to estimate its impact through preliminary forecasting. Is there a way to estimate the speedup or the theoretical limit to the increase in processes? Fortunately, there is, guided by the so-called Amdahl’s Law [2]. This rule allows us to understand the potential advantage we can gain from parallelizing a task and helps make informed decisions about whether parallelization efforts are worthwhile. Additionally, it underscores the importance of thoroughly analyzing sequential portions of the program that can be transformed into parallel paradigms to maximize overall performance.
\[S\left(n\right)=\frac{1}{\left(1-P\right)+\frac{P}{n}}\]where, \(S\left(n\right)\) is the theoretical speedup, \(S\left(P\right)\) is the fraction of the algorithm that can be made parallel \(S\left(n\right)\) represents the number of CPU threads. The visual relationship of this formula is illustrated below:
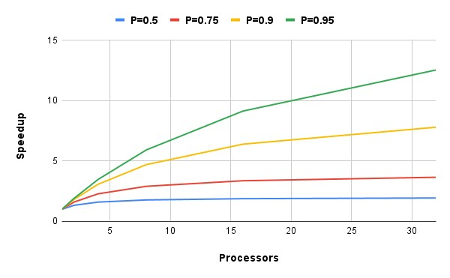
- Fig. 5. Global Interpreter Lock (GIL). The interpreter permits the execution of only one thread at any given moment.
In summary, the degree of speedup a program experiences with \(n\) processors depends on the portion of the program that can be parallelized, meaning it can be divided among multiple CPU cores.
How to cite
Askaruly, S. (2024). Basic parallelism in Python. Tuttelikz blog: https://tuttelikz.github.io/blog/2024/03/parallelism-1/
References
[1] Beazley, David. “Understanding athe python gil.” PyCON Python Conference. Atlanta, Georgia. 2010.
[2] Amdahl, Gene M. “Validity of the single processor approach to achieving large scale computing capabilities.” Proceedings of the April 18-20, 1967, spring joint computer conference. 1967.
Appendix
A1. Example of CPU-bound task
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
return False
return True
def find_primes(start, end):
primes = []
for num in range(start, end + 1):
if is_prime(num):
primes.append(num)
return primes
start = 1000000
end = 1001000
primes = find_primes(start, end)
print(primes)
A2. Example of I/O-bound task
import requests
def fetch_data(url):
response = requests.get(url)
return response.text
url = "https://api.example.com/data"
data = fetch_data(url)
print(data)